

Vi, vas četvoro, što čitate kolumnu, sjećate li se kad sam prije godinu dana napisao da se SEO igra promijenila? Pogriješio sam. Igra se nije promijenila – moguće da je zamijenjena.(šalim se, nema vas četvoro – skoro 400 ljudi čita redovno IMT kolumnu, na čemu sam vam zahvalan i vjerujem da vam koristi).
SEO I GEO su dvije različite mašine koje rade po dvijema različitim logikama, i optimizovati za jednu mehanikom one druge je gubljenje vremena i para.
- Brojke daju bolji kontekst: Y Combinator predviđa da će tradicionalni search volume pasti 25% do kraja ove godine i 50% do 2028.
- McKinsey procjenjuje da će kroz AI pretragu teći oko 750 milijardi dolara potrošačke potrošnje do 2028.
- Forrester je u martu objavio da već ‘94% B2B kupaca’ koristi ChatGPT, Claude ili Perplexity prije nego što odluče šta će kupiti.
Pa ipak, većina kolumni, stavova i Linkedin playbook post-ova o “GEO-u” (Generative Engine Optimization) prepakuje stari SEO playbook sa novim koricama. Lijeno i opasno. Hajde da probamo da raščlanimo o čemu se zapravo radi.
Kako AI pretraga zaista funkcioniše
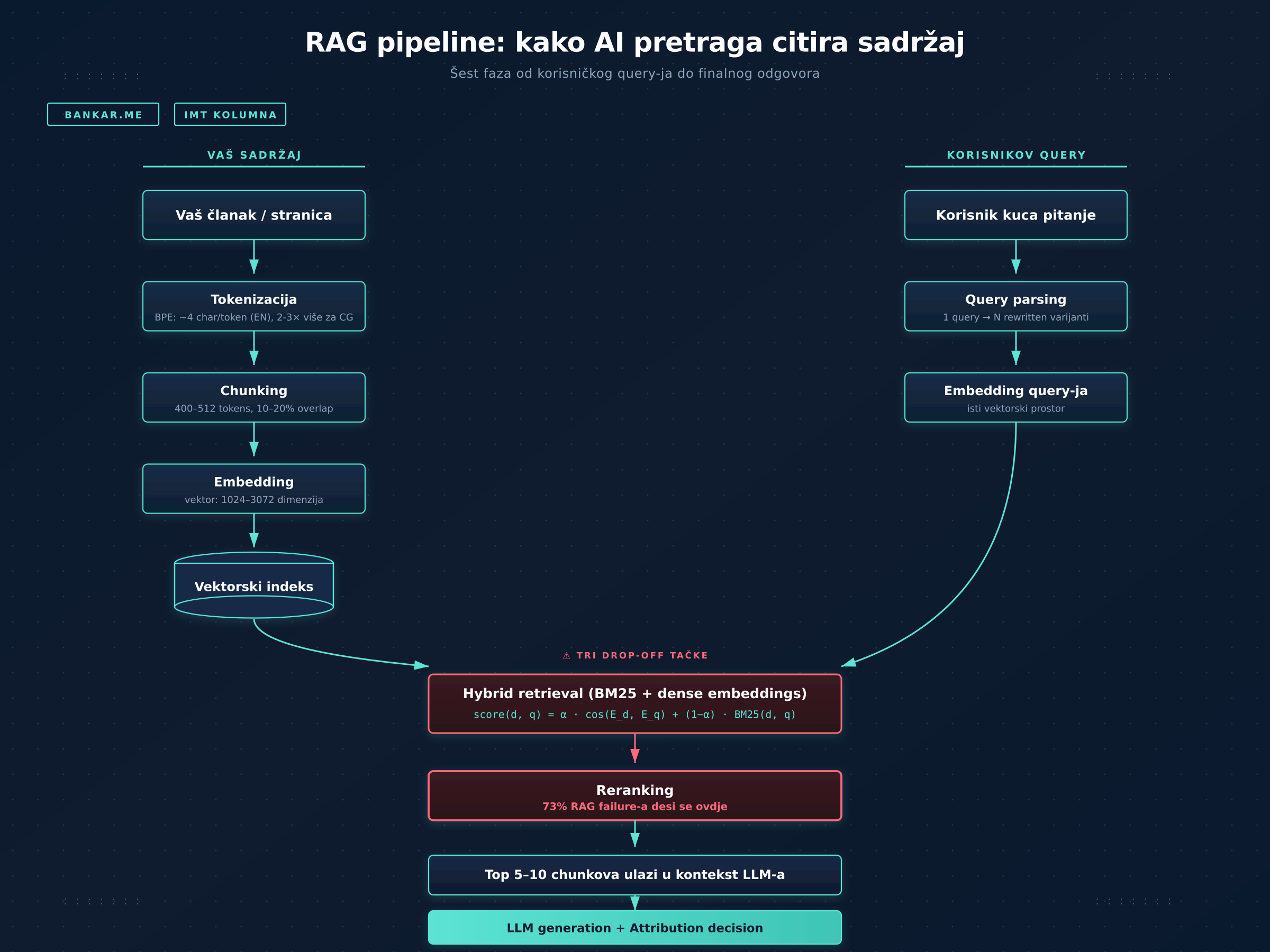
Mehanizam koji omogućava da ChatGPT, Perplexity i Google AI Overviews citiraju izvore zove se ’RAG’ (Retrieval-Augmented Generation) i radi u šest faza, ali ja ću se zadržati na onima koje vam mijenjaju strategiju.
Kad ukucate pitanje, LLM ga prvo prepiše u više varijanti koje paralelno pretražuju. Onda ide ‘hybrid retrieval’ – sistem istovremeno koristi BM25 (klasični keyword search) i dense embeddings (vektorska, semantička sličnost). Konačni score dokumenta `d` za query `q` izgleda (otprilike) ovako:
score(d, q) = α · cos(E_d, E_q) + (1−α) · BM25(d, q)
Parametar `α` obično pada između 0,5 i 0,7 u korist semantike. Drugim riječima — keyword više nije dovoljan, ali nije ni mrtav.
Slijedi ‘reranking’sa cross-encoder modelom koji preuređuje kandidate uzimajući autoritet, svježinu i strukturu u obzir. To je tačka u kojoj se odlučuje sve. Industrijska analiza za 2026. konzistentno pokazuje da kada RAG zakaže, otkaz se dešava u retrieval/rerank fazi u 73% slučajeva – ne u generaciji teksta.
Top 5–10 chunkova ulazi u kontekst LLM-a, on piše odgovor, a zatim dolazi ‘attribution decision’ – probabilistička odluka da li se brend naziv očuva u finalnom tekstu, ili se “skida” prilikom sažimanja.
Ono što treba zapamtiti: vaša stranica nije rangirana kao cjelina. Rangiraju se njeni djelovi — chunkovi — i najslabiji povlači cijeli dokument naniže. Ako vaš sadržaj nije citiran, najveći problem najvjerovatnije nije kvalitet teksta. Eliminisan je prije nego što je LLM uopšte stigao da ga vidi.
- Kako sadržaj postaje vektor
Tri transformacije kroz koje vaš tekst prolazi prije retrieval-a.
Tokenizacija. LLM ne čita riječi nego tokene — sub-word jedinice. Engleski je optimizovan za ovaj proces (1,2,3 tokena po riječi). Crnogorski nije. Empirijsko mjerenje koje sam sproveo na nekom MarTech tekstu od 458 riječi pokazuje:
53% više tokena u GPT-4o, 96% više u GPT-4* za isti sadržaj na crnogorskom u poređenju sa engleskim.
Razlog: dijakritike i padeži cijepaju riječi u 4–6 fragmenata. Riječ inteligencije postaje četiri tokena (`int`-`elig`-`enc`-`ije`); engleski intelligence je jedan.
Chunking. Standardni RAG chunk je 400–512 tokena. Praktično: chunk drži oko 415 engleskih riječi, ali samo oko 250 crnogorskih.
Embedding. Svaki chunk se pretvara u vektor (1.024–3.072 dimenzije). Mjeri se sa cosine sličnostima između −1 i +1, a top-K retrieval bira K najbližih chunkova vašem query vektoru.
Nezgodna posljedica: vaš sadržaj na crnogorskom mora biti dvostruko gušći u suštinskim informacijama po riječi da bi se takmičio za isto mjesto u kontekstu kao engleski tekst. Razvodnjavanje uvodom — već skupo na engleskom — postaje fatalno na crnogorskom.
Zašto baš jedan chunk biva citiran
Pretpostavimo da je vaš sadržaj prošao retrieval i ušao u kontekst. Posao još nije završen — pred LLM-om je 5–10 chunkova različitih izvora, a citaće se možda samo 2–3.
Zhihua Tian i kolege u martu ove godine objavili su rad ‘Diagnosing and Repairing Citation Failures in Generative Engine Optimization’ u kome identifikuju fundamentalnu grešku većine GEO praksi: postojeće metode mjere koliko dokument ‘utiče’ na odgovor – a ne mehanizam koji zapravo vraća promet kreatorima, što je ‘citacija’. Vaš tekst može da promijeni AI odgovor, ali ako brand naziv ne ostane u finalnom tekstu sa linkom, niste dobili ništa.
Tri kriterijuma dominantno odlučuju ko biva citiran:
‘gustina nove informacije’ (sadržaj koji se preklapa sa onim što LLM već zna biva preskočen — vaše interno istraživanje, lokalni podaci ili anketa među klijentima su zlato)
‘specifičnost činjenica’ (konkretni brojevi, datumi, imena)
‘strukturalna izolovanost’ (može li se chunk razumjeti bez prethodnog konteksta). Ako koristite ‘to znači da…’ bez antecedenta (opisa ranijeg događaja recimo) u istom paragrafu, gotovi ste.
Razlike po platformama — i poprilično druga struktura za e-commerce
Iste taktike ne rade jednako svuda. Svaka generativna pretraga je posebna mašina sa različitim izvorima:
Pregledi par signala po glavnim LLM alatima:
- ChatGPT | Google Shopping + Bing index | OAI-SearchBot | Use-case match, structured data |
- Perplexity | Real-time web crawl | PerplexityBot | Citation iz nezavisnih izvora |
- Google AI Overviews / Mode | Google index + Merchant Center | Googlebot | Intent + lokalni inventar |
- Microsoft Copilot | Bing + Edge browser data | BingBot | Cijena + dostupnost |
- Amazon Rufus | Zatvoreno: review-i unutar Amazon-a | | Review sentiment |
Postoji i druga važna razlika. Kada korisnik pita ‘objasni mi razliku između OLED i QLED’, pokreće se content RAG koji sam upravo opisao. Ali kada pita ‘koji je najbolji 55-inčni TV do 800 evra’, aktivira se ‘shopping pipeline’ — drugi mehanizam, sa drugim signalima. Tu dominira off-site autoritet (industrijska istraživanja navode da 91% AI citation-a za product recommendations dolazi sa Reddit-a, recenzija i ekspertskih blogova), a zastarjeli podaci o cijeni ili dostupnosti mogu da isključe prodavnicu i kada je sve ostalo savršeno.
Profound-ovo istraživanje na više stotina miliona citata pokazuje i razlike po izvoru: Wikipedia vodi ChatGPT citate sa 7,8%, dok Reddit dominira na Google AI Overviews (2,2%) i Perplexity (6,6%). Praćenje samo jedne platforme je pogrešno.
Što stvarno funkcioniše
Princeton, IIT Delhi, Georgia Tech i Allen Institute of AI testirali su devet tehnika optimizacije na 10.000 query-ja u sistemu koji simulira BingChat. Tri vode tabelu:
- Cite Sources — eksplicitno citiranje vjerodostojnih izvora unutar samog teksta — donosi do 115% rasta vidljivosti za sajtove koji su niže rangirani u tradicionalnoj pretrazi.
- Statistics Addition — konkretne brojke, datumi, procenti — povećava vidljivost do 40%.
- Quotation Addition — kratki citati eksperata — slično djeluju kao statistike.
Tehnika koja ‘šteti’: Keyword stuffing, posljednja od devet u Princeton studiji. LLM-ovi koriste semantičko, ne leksičko podudaranje — ponavljanje istih riječi razvodnjuje semantičku gustinu chunk-a.
Princeton dodaje još tri: ‘BLUF struktura’ (direktan odgovor u prvih 40–60 riječi paragrafa), ‘samostalni paragrafi’ (svaki H2 mora biti čitljiv izolovano), i ‘information density’ – dodajte podatke koje LLM nema u trening setu.
Za e-commerce, prioriteti su drugačiji. Off-site authority dolazi prvi: brendovi pomenuti pozitivno na 4+ nezavisnih izvora se 2.8 puta češće pojavljuju u AI odgovorima. Use-case opisi će potući feature-listu svaki put – ‘pogodno za stanove do 60 m²’ povlači citation za query ‘šta da odaberem za…’; tehnička specifikacija ne.
I treće, sinhronizacija cijene i zaliha postaje SEO/GEO problem, ne više samo operativni.
Tehnička infrastruktura
Sve gore navedeno ne radi bez čiste osnove. Tri stuba koja morate imati.
JSON-LD strukturisani podaci drže preko 89% tržišnog udjela — AI crawler-i ih parsiraju kao standalone podatak. Ključni schema tipovi za 2026: `Product`, `Organization`, `FAQPage`, `Review`, `BreadcrumbList`. Bez bar `Organization` i kontekstualnog tipa, vaša stranica je polu-nevidljiva.
Entity consistency. LLM-ovi grade interni knowledge graph o vašem brendu kombinujući Wikipedia-u, Wikidata-u, vaš sajt, social profile i schema. Nedosljednost imena ili adrese je signal sistemu da ima posla sa više različitih entiteta – i nijedan ne dobija puni autoritet.
Crawler kontrola. OpenAI ima dva odvojena crawler-a:
- AI-SearchBot – indeksira sadržaj za ChatGPT pretragu i preporuke
- GPTBot – prikuplja podatke za treniranje budućih modela
Search bot vam donosi citate i atribuciju — training bot uzima vaš sadržaj bez ikakve atribucije.
Preporuka: dozvolite OAI-SearchBot i PerplexityBot, blokirajte GPTBot. Default WordPress, Magento i Shopify instalacije obično ne razlikuju ova dva.
Mjerenje
Pozicija ključnih riječi mjeri ono što više nije primarni kanal otkrivanja. Pratite četiri nove metrike:
- citation frequency
- citation context (kako AI opisuje brand)
- share of voice u odnosu na konkurenciju
- AI referral traffic
Alati su raspoređeni u četiri sloja.
Nulti sloj — server log monitoring AI bot crawler-a, GA4 sa filterima za AI referral, plus manualne nedjeljne pretrage — košta nula evra i preporučujem da svi tu počnu.
Iznad toga su entry tier specijalizovani citation tracker-i, srednji tier alati za teme sa marketing analitičarem, i enterprise tier za kompanije sa AEO budžetom već iznad pola miliona evra.
E-commerce zahtijeva specijalizovane alate za carousel placement (Alhena AI, Siftly, Parcel Perform AI Visibility Index) — klasični citation tracker-i ovdje nisu dovoljni.
Što sve ovo znači za biznise u region
Pet nalaza specifičnih za nas, koje globalna GEO literatura ne pokriva:
Token-overhead je strukturni hendikep. 53–96% više tokena za isti sadržaj na crnogorskom znači da je razvodnjavanje luksuz koji ne možete sebi dozvoliti.
Trening podaci o regionu su rijetki. Mač sa dvije oštrice. Konkurencija u modelu je manja, lakše je biti citiran kao primarni izvor za regionalne teme. Ali sistem je manje siguran u svoje odgovore i češće halucinira nazive, cijene i činjenice — što vašem brendu može da naškodi i kad ste sve uradili kako treba.
Reddit i Wikipedia su za nas drugačiji izvori.
Po istom principu po kojem dominiraju globalno, lokalni Reddit-ekvivalenti (Forum.hr, regionalni subreddit-i poput r/serbia, r/croatia, r/montenegro, r/bosnia) i Wikipedia-stranice na našim jezicima su podcijenjene investicije.
Cross-language citation transfer postoji. Brendovi sa minimalnim engleskim sadržajem (about page, top 10 product description-a, FAQ) dobijaju značajan preliv autoriteta nazad u lokalne odgovore.
Google Shopping nije pristupan u CG, RS i BiH do najavljenog uvođenja u septembru 2026. Pošto ChatGPT crpi 75% product recommendation podataka iz Google Shopping feed-a, regionalni e-com igrači su trenutno strukturno isključeni iz ChatGPT shopping carousel-a — bez obzira na kvalitet kataloga. Možda direktan product feed u GPT Ads ubrza stvari.
Crna rupa
Završavam sa onim što me lično najviše brine. Po Opascope analizi iz 2026, 70–90% shopping journey-a se sada dešava prije bilo kakve interakcije koju možete izmjeriti. Sa AI agentima koji kupuju u ime korisnika, ta brojka se približava 100%. Nemate click. Nemate sesiju. Nemate add-to-cart event. Prvi signal je, recimo, order webhook.
To znači da i najbolji tracking-tool danas ne može da vam kaže koliko ste puta razmatrani a odbačeni, koje konkurente su agenti uporedili sa vama, ili šta je presudilo. Svaka GEO investicija mora biti svjesna ove svojevrsne crne rupe.
Pa zašto onda investirati? Zato što je alternativa potpuna nevidljivost u kanalu koji raste hiljadu posto godišnje, posebno ako je konkurencije počela ranije gradi ‘compounding citation’ autoritet.
Kao kod organskog SEO-a prije petnaest godina, prozor za sticanje strukturne prednosti u našem regionu trenutno je otvoren — ali se neće dugo zadržavati u tom stanju.
Tradicionalni SEO ne umire. Postaje second-best. Razlika između rangiranja stranica i citiranja rečenica više nije tehnička sitnica — postaje strateška pozicija koja će razdvojiti brendove koji opstanu od onih koji polako izblijede iz rezultata, kojih jednog dana neće više biti.
Paradoksalno, to vjerovatno ne slabi SEO industriju — već joj daje novu važnost. Jer upravo su SEO stručnjaci najbliži razumijevanju kako sistemi otkrivaju, interpretiraju i dodjeljuju autoritet informacijama u eri AI pretrage.
Autor: Nikola Pelević (MarTech i Ecommerce Expert sa preko 10 godina iskustva u marketing tehnologijama, digitalnom marketingu i ecommerce oblastima. Trenutno obavlja funkciju izvršnog direktora Djak Sport Crna Gora, digitalnog konsultanta na nivou Ðak Sport Grupe i osnivač je Clavis Advisory, agencije za marketing tehnologije, AI primjenu i e-commerce)









